cluster mass tests
EEG and MEG studies are facing the
problem of the inflation of type I error due to multiple testing
whenever several time points or sensors are screened for an
effect. One solution for this problem is the use of a
non-parametric cluster mass test on surrogate statistics of the
original data set. Using this procedure, the peak areas and
intervals of an effect can be identified through a single test,
which compares the largest occurring cluster mass in a dataset
with the randomly occurring maximum cluster masses in permutations
of the original dataset, that represent the null-hypothesis of no
effect.
EMEGS offers the possibility to calculate statistical parameters
based on permutations of an original dataset for a range of
statistical tests: t-tests, correlations, custom hypothesis
F-contrasts and full-factorial ANOVA F-tests. Cluster mass tests
usually involve two processing steps: 1) the calculation of
statistical parameters for the original datasets and for a number
(usually 200-2000) permutations of this dataset 2) the
identification of peak spatio-temporal clusters in these
parameters. For ANOVA F-tests, both steps are configured and
initiated from the rmANOVA window which can be opened from the
emegs2d control window or from the emegs3d Calculate\Repeated
Measures ANOVA menu. For t-tests, correlations and contrasts, the
parameter calculations must be started from the corresponding
emegs2d\Calculate menu items. The cluster identification is then
performed from the rmANOVA window just as for ANOVA F-tests.
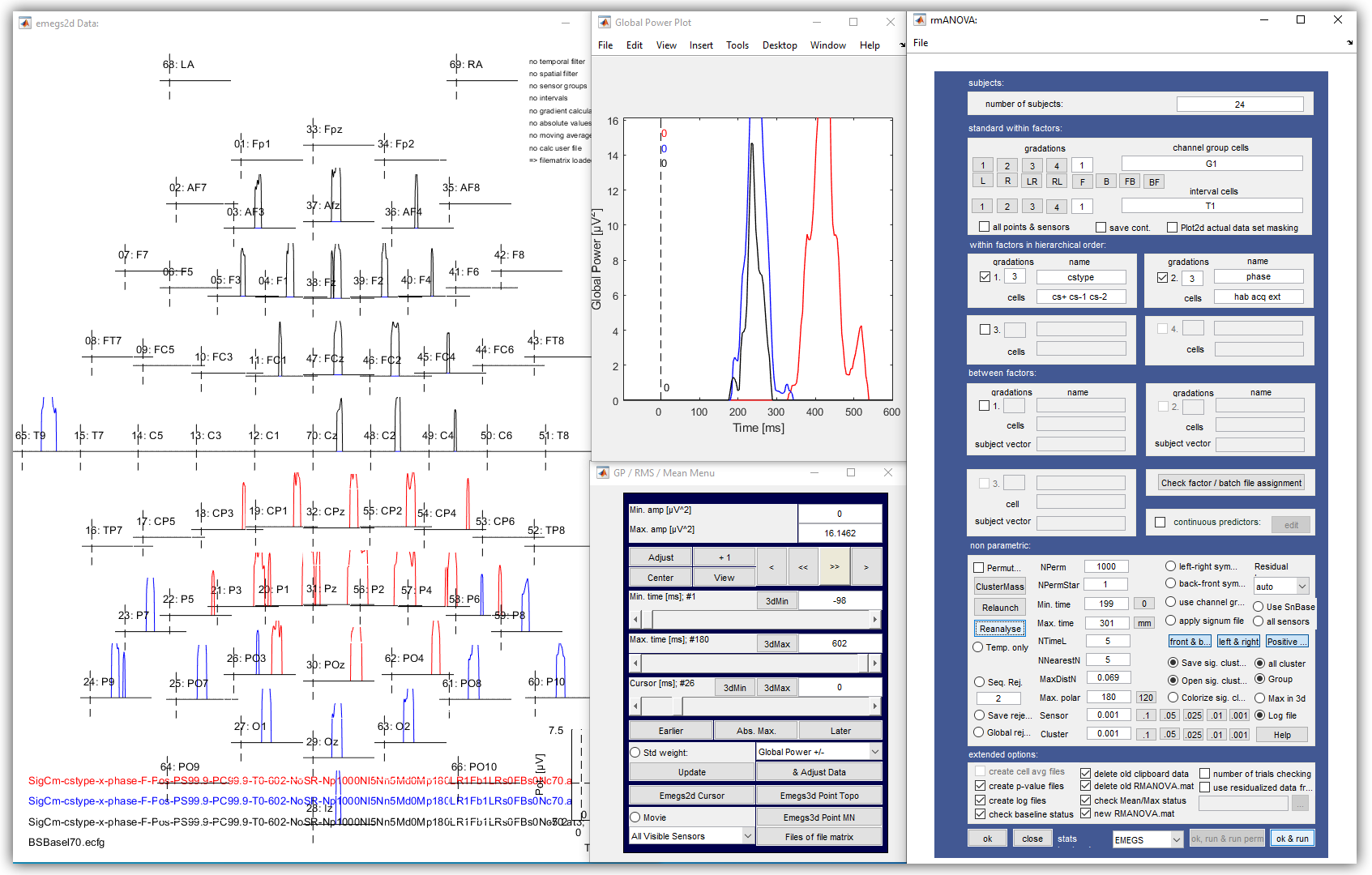
A step-by-step instruction for ANOVA F-tests is given below:
- Open EEG or MEG sensor or source space EMEGS *.at* files in
emegs2d.
- Run the ANOVA WITHOUT random permutation ("Permutation
analysis" in "non parametric" menu disabled) and save the
results in a folder of your choice (named XXX for example)."
Enable "all points & sensors" ("standard within factors")
and disable "Permute analysis" ("non parametric"). Select
"EMEGS" as stats backend and hit "o.k. & run". (This analyis
will create output files for all main effects and interactions
(F- or t- and p- values) in the XXX/STATS subfolder as well as
all cell averages in XXX/CAVG).
- Enable "Permutation analysis" in the "non parametric" menu. As
cell means, p-values and log files are not used for the
Monte-Carlo test, these setting are disabled by default in
extended options. Run the corresponding analysis WITH random
permutation and save the results in the same XXX folder (not in
any subfolder or different folder). (This will create output
file(s) in XXX/STATS-0001, XXX/STATS-0002, XXX/STATS-0003
subfolders). The number of permutations are defined by "NPerm"
(e.g. with 1000 up to ... XXX/STATS-1000). If the permutation
stopped by mistake before creating the final loop restart the
loop with corresponding NPermStart and NPerm settings. (e.g.
abortion at STATS-0801 => delete STATS-0801 and restart the
loop with NPermStart=801 and NPerm=200. (if XXX/CAVG files have
been created unnecessarily, the "create cell avg files" option
has been enabled).
- The further analysis is based on these permutations. Please
wait for all loops.The message figure and command window output
informs about the estimated calculation time for all NPerm
loops.
- Run "ClusterMass" (non parametric) in order to evaluate masses
of spatiotemporal clusters for a main effect or interaction of
interest.You may select F-value or t-value files.As F-values are
always positive please choose "Positive values" in the "non
parametric" menu. For t-values of t-tests, contrasts or
correlations you may test for positive or negative t-values by
toggling this choice.For F-values, push the "ClusterMass"-button
and select a single F-file (main effect or interaction - not a
p-value file)of the corresponding non-permutated test from the
XXX/STATS-folder.
Before set the desired "MinTime" and "MaxTime" in the "emegs3d
Menu" to define the start and endpoint of the interval of
interest to be scanned.
You may select the entire range if you have no a-priori
hypothesis with repect to the timing of the effect. In the
"rmANOVA-non parametric" menu, select to scan only front
sensors, only back sensors, or all sensors if you have no
a-priori hypothesis about the region of interest. Similarly
select only left, only right or both left and right sensors if
you have no a-priori hypothesis about the hemisphere of
interest.
Choose "NTimeLag" (in time points) as further cluster setting.
The analyis will ignore data of sensors with consecutive
significant values of shorter lifetimes (i.e. < NTimeLag).
Choose "NNearestNeighbors" (number of nearest neighbors) as
further cluster setting.
The radius of virtual spheres around each individual sensor gets
increased until the maximum number of spheres contain
NNearestNeighbors adjacent sensors (note that the number of
neighbors may vary depending on the sensor (source) grid e.g.
sensors at the grid border have fewer neigbors). The
corresonding radius of this sphere is given as MaxDistNeighbors.
You may also define the radius and receive the maximum number of
nearest neighbors.
Please note that the algorithm might consider significant
sensors next to adjacent even insignificant sensors if the
radius exceeds its distance to this one (i.e. bridging of
neighboring clusters).
You may choose "Max. polar angle" as further cluster setting.
Sensors at the top (e.g. Cz) of the volume conductor have a
polar angle of 0, sensors at the bottom 180 degrees.
Sensors more inferior than this angle will be ignored (e.g.
estimated sources within regions not sufficiantly covered by
sensors)
You may choose "emegs3d Menu/Interactive Sensor Grouping" to
identify a reasonable setting.
You may choose "use channel groups" as further cluster setting.
The analyis will ignore sensors which are not group members.
(e.g. exclude estimated sources within other regions not
sufficiantly covered by sensors, such sources in face areas)You
may choose "left-right symmetry" as further cluster setting. The
cluster algorithm may extend the cluster volume by
spatiotemporal bridging to a contralateral area. (i.e. left and
right symmetric regions may build a single cluster although not
spatially adjacent, which allows to take a priori information
about left-right symmetries into consideration.
You may choose "back-front symmetry" as further cluster setting.
The cluster algorithm may extend its volume by bridging from
back to front or vice versa. (allows to take a priori
information about anterior-posterior symmetries into
consideration. (e.g. Early Posterior Negativit => posterior
negativity combined with anterior positivity) (symmetric cluster
with polarity shift are identified by F-values only)
The algorithm identifies spatiotemporal clusters at sensor or
source level meeting the first significance criterium at sensor
level for each random permutation.
("Sig. crit. sensor; e.g. p-sensor < 0.05"; "sensor" in this
sensor siginificance level should not be confused with sensor
space, it holds for both sensor and source space).
The mass of a spatiotemporal cluster is defined as sum of all
statistical values (F or t) within this spatio-temporal cluster
(the integral).
The biggest cluster mass of each permutation is used to evaluate
the sorted distribution tested with the second significance
criterium at cluster level.
(the spatiotemporal a-priori settings (e.g. time interval)
impacts the biggest cluster mass of each permutation modulating
the distribution (i.e. most conservative with all points and
sensors)
("Sig. crit. cluster; e.g. p-cluster < 0.05").
With 1000 permutations and p-cluster < 0.05 a spatiotemporal
cluster is valued as significant if 950 of the biggest cluster
of the random permutation have smaller masses.
Command window and message box will inform you about identified
significant clusters.
Subdirectories with setting specific names will be created in
the XXX/STATS folder: CM- Name of tested effect - PS (1-p)x100
sensor sig. crit. - PC (1-p)x100 cluster sig. crit. - T interval
in ms
Within these subdirectories significant spatiotemporal cluster
are stored as emegs .at files with size dependant numbering (at1
is biggest) and file names identifying all settings.
A log file with settings and results of each analysis is stored
in this directory.
In case of signifcant clusters, the corresponding sensor groups
are identified: You may choose "emegs3d Menu/Interactive Sensor
Grouping" to examine and potentially store these groups.
(sensor groups of the biggest four clusters only are stored in
"Interactive Sensor Grouping")
For post-hoc analyis and visualization of effects you may open
the .at files of significant clusters in emegs2d. You may choose
emegs2d/File/Open Data Set/Open i+/- j Set for multiple cluster.
Choose "emegs2d/Calculate/Channel groups/Interactive ... based
on actual Plot2d data set to identify the channel group of the
actual Plot2d data set cluster in "Interactive Sensor Grouping".
For post-hoc examination of single or multiple clusters (e.g.
interactions between clusters) you may choose the "standard
within factor" analysis".
For single cluster you may enable the "Plot2d actual data set
masking" (dependent an a cluster given at the actual Plot2d data
set.)
This setting calculates the integral within the given cluster.
Otherwise the integral of the senor group between min. and max.
points in emegs3d is calculated.
This setting is currently applicable for single cluster only.